Who’s Reading The Code? Code Quality in the AI-First World.
The Analogy: Compilers#
I am almost (haha) old enough to have been exposed to handwritten assembly language, and when I played with compiler tech, I could see a big difference in the assembly code a compiler wrote versus hand-written and manually optimized assembly.
The handwritten version was structured for human comprehension. Meaningful labels, comments explaining intent, code organized in a flow that tells a story, (re)using patterns that assembly developers know and recognize. A thing of beauty (really, handwritten assembly can be an art, especially in the world of very limited CPUs where each cycle matters, but I am deviating).
A compiler is a brute force machine that has a very different output, that isn’t structured for readability, and uses generic pattern and template based flows, includes boilerplate code, meaningless generated labels, algorithmic register allocation strategies, etc… Resulting in predictable output that can be very verbose. The compiler doesn’t have the mental model the human coder has, uses systematic micro optimizations instead of intent based specific optimizations, etc…. So readability is gone, and in the early days of compilers, I am sure assembly developers would look with hawk eyes at generated code, scrutinizing it and discussing the merits and beauty of human, smart, hand crafted assembly code.
But do we still read/review the output of our compiler? I think not, I am not even sure, with all the levels of abstraction in our code generating/executing pipelines, where I would need to look :-). Readability of that code is of no meaningful concern to anyone, and we just trust the output.
AI Generated Code: Another Level of Abstraction?#
Lately, LLM Assisted code generation has reached levels of quality that make companies look at the process of writing code in a very different way. And like any fundamental shift, it doesn’t happen in one jump. It’s a progression, and I think we can see three clear steps.
First, AI was (is?) used in a way that it supports the software engineer who wrote the code. This generation of AI Assisted workflows autocompletes, generates boilerplate code, reuses patterns the models are trained on, but ultimately the engineer pushes changes that he/she has crafted and reviewed, supported by prompting the AI tools. The burden shifts from actually handwriting code to instructing and babysitting the tools, and it becomes harder and harder to understand all code written, in the same way we understand fully manually written code.
And then it shifts, we move up the AI maturity ladder and start using agentic tools that can autonomously generate larger pieces of code and we shift from iterative prompting to structured workflows of defining intent to the AI tools, so they can more consistently and autonomously build code that closely follows that intent. In that process, it becomes much harder to read all code that is generated, and we need to rely even more on the guardrails that we define to guarantee that the code doesn’t deviate from what we want it to do.
So after that we switch to multi-agentic, intent driven and spec driven workflows that generate so much code, that we have to admit that we don’t read (all of) “our” code anymore, so that’s where we (some of us) are now. Like the assembly developer, looking at the large blurbs of machine code that he/she can’t read line by line anymore, and at some point has to trust the output.
Of course the analogy is only structural, and there are differences. A compiler works in a way we can completely understand, and it is fully deterministic. The same source code will have the same output, each time we compile it. The AI Tools are based on LLMs and are far less predictable and, more fundamentally, not formally verifiable. In the most pessimistic view, they are statistical machines that predict the next token/word and have no verifiable model of correctness, no formal guarantees. In the most optimistic view, the LLMs, because they are based on neural networks, are simulations of the core mechanics of animal/human brains and thus have the same mysterious depths and will soon reach a level of consciousness and comprehension that puts them on the same level as us, humans, or even higher (AGI). I think the truth is rather somewhere in between, but that is a whole other discussion.
What is Quality of Code in the AI Era#
So, here we are now, on a point where we are shifting to processes where we want to let AI generate our code and stop reading it. This is a trust transition, going from a combination of relying on humans to read code, and guardrails that we can automate that guarantee certain boundaries of quality, to humans auditing the boundaries they define instead of the internals, relying completely on the guardrails to verify those internals.
In fact that is a transition that has been going on for a while. While human review was an important part of the process, if we wanted predictability and measurability we already needed those guardrails in place. The difference now is that we will have to rely on them completely, cutting out the human code-reading reviewer more and more.
And that changes what code review itself looks like. If reviewing AI-generated implementation line by line is like reviewing compiler output, then review needs to shift upstream: to the specifications, the test suites, the type contracts, the interface definitions. We stop reviewing what the code does and start reviewing what we told it to do. That is a fundamental change in how engineering teams spend their time.
So what impact does that have on our definition of quality of code, because we need to put even more guardrails in place, and make the existing ones stronger, but what are the characteristics and metrics that we have to guard, if a human won’t read our code? Which are the signs that stay important, what characteristics are not so relevant anymore, and are there any emerging metrics, that were not (so) important before? My take below.
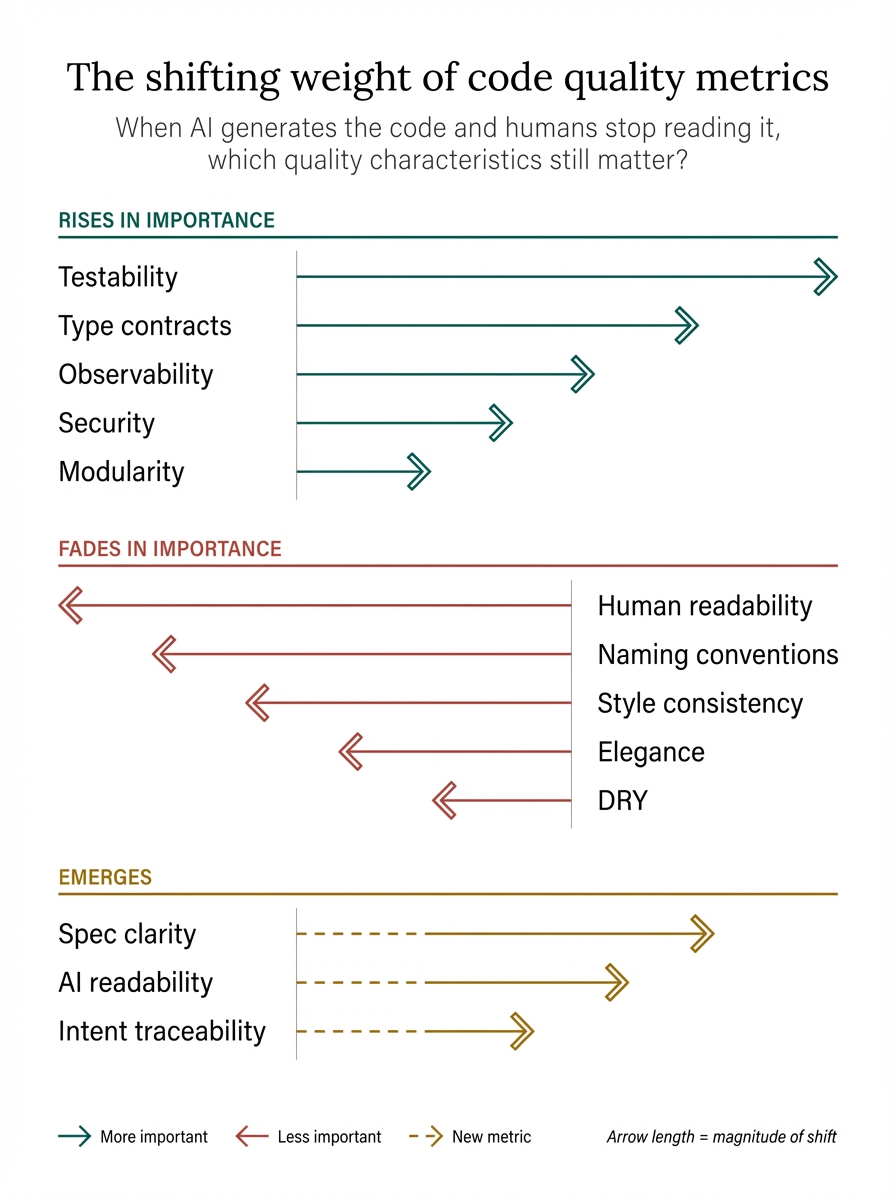
What Matters More Than Ever#
Testability#
Tests become more than a guardrail, they become the executable definitions of the intent. Therefore they are artifacts that are part of the source code, part of the specification. But this is an emerging field more than ever, because we need to emphasize other metrics, here a few:
Behavior coverage versus Code coverage? We might need to look more at mutation testing scores: if we inject faults in code, are they caught by our tests?
Specification versus implementation ratio? How much of the code base is specification related (types, contracts, schemas, assertions, …) versus implementation related. The higher this ratio, the more boundaries can be reviewed / inspected by humans. There is no formal metric for this, as far as I know and that feels like a gap the industry needs to close.
Correctness / Verifiability#
We always cared about correctness, obviously. But the way we verified it is changing. “I read the code and it looks right” was a real verification method, whether we admitted it or not. That method is disappearing. What replaces it is a combination of all the other characteristics in this section: tests that prove behavior, types that constrain possibilities, monitoring that catches deviations. Correctness doesn’t change as a goal, but the path to confidence in it changes completely.
Type Safety / Contracts / Interfaces#
When we talk about specification versus implementation ratio, we touch an important point. Types, contracts and interfaces become our machine readable specifications. These are not only the boundaries we humans can check and understand, but they are also executable specifications. Compilers will warn / fail if the code doesn’t comply with them. Type safe languages may have an advantage here.
Modularity#
AI can work better with small well defined “slices” of functionality, so more than ever, we need small well-bounded units with clear interfaces. Strong module boundaries, again, but this time it’s not (only) about team organization but about AI-digestibility. This applies at every scale: function boundaries, package boundaries, service boundaries. You can have excellent modularity in a monolith.
Security#
Another big one that grows in importance. AI can easily create code that looks safe on first look, but can introduce subtle vulnerabilities. Security scanning tools become ultra-important. There is also a supply chain dimension here: AI models are trained on vast amounts of existing code, including code with known vulnerabilities. They can replicate insecure patterns not out of malice but out of statistical likelihood.
Observability#
And also, when we shift from reading how code does things to observing what code does, we need first-class observability. Logging, monitoring, tracing, … becomes even more important.
When we don’t read the implementation, the running system is a black box, and observability is what makes that black box auditable. It becomes our runtime counterpart of the specification: specs define what should happen, observability reveals what does happen. And the cost equation changes as well, when AI generates the code, adding deep instrumentation is cheap, so the trade-off that kept observability thin in many projects disappears.
What is Less Important#
Human Readability#
This is hard to swallow. Coding by humans has become an art in a way that writing code that our brain can understand is a skill that is very important to the review process. It has become the joy and pride of many software engineers, and it feels sad, as a coder, to let that go, because when AI writes AND reads code, it is not important that the code is optimized for human scanning. AI “looks” different at code and has other cognitive/semantic limits than we do. (Important: we are talking about implementation readability, not about readability of interfaces and types see above).
Naming Conventions#
Internal variable and functions don’t need recognizable names. AI doesn’t need the extra layer of clarification of what’s the role of an identifier in a piece of code, because the code already reveals this. External names where humans interact with, do still matter.
Comments About the What#
Again, the code explains what the code does best. If comments are about intent, or the why of code, they can still be important though!
Style Consistency#
Tabs versus spaces, brace placement, line length, etc… all style characteristics that we keep consistent and optimized for human readability. If no human reads it regularly, who is style for? Some style rules that prevent bugs (like mandatory braces) remain relevant, but the aesthetic dimension isn’t important anymore.
DRY#
Humans are particularly bad at keeping different copies of the same code/pattern in sync. For AI that is not so important anymore, so we might drop DRY principles, especially when they require a level of abstraction / reusability plumbing that might increase complexity for the sake of de-duplication. To be clear: DRY still matters for the human-authored artifacts, the specifications, contracts, and type definitions. It’s implementation-level DRY that becomes less sacred. Duplication in generated code that is independently testable might actually be preferable to clever abstractions that create hidden coupling.
Elegance#
Well, AI doesn’t care about how elegantly designed or clever a piece of code is, if it does what our intent expresses, including the non-functional intent, it is “happy”. This is something that sort of collides with our feelings of “job satisfaction”, and is a part of a skill set that we learned to admire. In fact, clever or unusual code patterns might be worse for AI, which works best with predictable, boring, straightforward implementations. “Clever” may shift from a compliment to a smell.
What is New#
AI Readability#
We don’t need humans to read our code, we need AI to understand it, so the code has to be consistently structured, strongly typed, explicit rather than implicit. We need to avoid magic values, implicit conventions, dynamic meta programming. You might think the AI knows this since it is now generating the code that some form of “itself” has to review later, but that is not how LLMs work. Each invocation of an LLM starts fresh, with no memory of previous sessions. The AI that generates code and the AI that later reads or modifies it are separate invocations with no shared context. Code that is structured, typed, and explicit gives each fresh invocation more to work with. That’s why AI readability matters even when AI wrote the code in the first place.
Specification Clarity#
The interfaces, types, tests, prompts, specs, …. they become the “real” code, and the generated code is a byproduct! We shift from writing efficient implementation to writing efficient specs, test suites, type definitions, behavioral contracts. Intent is the keyword.
Boundary-Level Audit-ability#
As humans move to reviewing behavior and contracts, API design quality becomes more important. Systems need to be designed in a way that correctness can be verified at the boundaries. We need to define how we can prove a “module” does its job without looking at the code.
Level of Determinism#
If AI generates the code, can we regenerate it from the same specs, again and again, and get equivalent results? How can we improve this predictability? This connects back to the compiler analogy: a compiler is fully deterministic, same input always gives same output. We’re not there with AI generated code, and maybe we’ll never fully get there, but moving along that spectrum, from chaotic to predictable, is a quality characteristic we need to measure and improve.
Intent Traceability#
We need ways to trace all the way from running code back to the human intent that produced it. The chain runs: human intent to specification to AI-generated code to running system. Every link needs to be traceable. This is a new form of (auto generated) documentation that doesn’t explain what the code does, but what intent / specification it originates from.
What This Means Beyond the Code#
A few consequences that follow from all of the above, that are worth thinking about:
Technical debt changes meaning. If you can regenerate implementation from specs, debt in the implementation is cheap to fix, just regenerate. But debt in the specifications and tests becomes the real killer. Bad specs mean perpetually wrong generated code, and no amount of regeneration fixes that.
The junior developer question. If nobody reads implementation code, how do juniors learn the craft? I think this mirrors the exact anxiety assembly developers had when compilers arrived. The answer, probably: you learn at the new abstraction level. Future developers learn to write specifications, tests, and contracts. The skill shifts, it doesn’t disappear.
Compliance and auditing. Auditors currently review code. What do they review when code is generated? This is an open question without good answers yet, and one that regulated industries will need to address soon.
The Source Code is Shifting#
So where does this leave us? I think the most fundamental shift is this: what we call “source code” is changing meaning.
For decades, the source code was the implementation. The thing a human typed, character by character, that a machine would execute. We reviewed it, we styled it, we took pride in it. It was simultaneously the specification of what should happen and the artifact that makes it happen.
That coupling is breaking. The implementation is becoming a generated artifact, like assembly became a generated artifact when compilers took over. And the “real” source, the thing that carries the intent, is shifting to the specifications: the types, the contracts, the tests, the prompts, the interface definitions. That is what humans will write, review, and maintain. That is where our craft needs to move to.
This is not a small shift. We have built an entire profession, with its values and aesthetics and identity, around the art of writing implementation code. Letting that go feels like a loss, and I think it is one, in the same way that handcrafted assembly was a genuine art that we lost when compilers took over. But we gained something bigger: the ability to work at a higher level of abstraction, to build more complex systems, to focus on intent rather than mechanics.
The transition won’t happen overnight, and it shouldn’t. We need better testing frameworks, better specification languages, better tooling for boundary-level verification. We need to develop the metrics we don’t have yet, like specification-to-implementation ratios and mutation testing benchmarks. And we need to build trust, the same way we built trust in compilers: gradually, with evidence, differently for different domains.
But the direction is clear. The question is not whether we’ll stop reading all our implementation code. We already have. The question is whether we’re building the right guardrails, specifications, and verification systems to make that transition safe.
Because in the end, nobody mourns the loss of hand-optimized assembly code anymore. We just build better software at a higher level. And that’s where we’re heading again.